The Challenges of Large Dataset Management
In my experience, I have faced many challenges with apps that needed to store a large dataset to continue functioning in weak or no-network environments and later synchronize to a remote server.
One of the pieces of feedback that I received was about an Android device that was slow when performing a scanning function via the scanner to search for a list of relevant customers. After investigating, I noticed significant slowdowns in query performance as the data grew, leading to a poor user experience.
To address this issue, I explored various optimization techniques and found that indexing is one of the keys to improve performance in our database.
In this article, we will explore how indexing works in SQLite, differentiate the performance when applying indexing, and experiment with scenarios where it may break the utilization of the index.
Defining and Populating the Example Table
First, let’s define a table to demonstrate in our example. Here I have a song table with id as a primary key, which is indexed by default, and the rest, name of the song and artist and popularity of the song are not indexed.
In this example, I use Android Room to experimentation, but under the hood the SQLite works similarly across all devices.
@Entity(tableName = "song")data class SongEntity( @PrimaryKey @ColumnInfo(name = "id") val id: Long , @ColumnInfo(name = "name") val name: String, @ColumnInfo(name = "artist") val artist: String, @ColumnInfo(name = "popularity") val popularity: Int,}Next, let’s populate some data. We have three artists: Jane, Emily and Justin with five songs.
| id | name | artist | popularity |
|---|---|---|---|
| 1 | Mock SYMPHONY | Jane Doe | 3 |
| 2 | Object Music | Emily Brown | 1 |
| 3 | Prototype Harmony | Emily Brown | 5 |
| 4 | SAMPLE song | Justin Nguyen | 9 |
| 5 | Untitled MELODY | Justin Nguyen | 7 |
Now, let’s look at a simple query to find a song by name:
SELECT * FROM song WHERE name = 'Untitled MELODY'Without an index on column name, to search for keyword “Untitled MELODY”, the database needs to perform a full table scan by reading each row sequentially to find the match condition.
This will be slow when dataset grow with the time complexity of a full table scan is O(n).
How Indexing and B-trees Improve Search Performance
To improve the search by name function, we add an index for the column name. Here is our example table with the added index in Android Room.
@Entity( tableName = "song", indices = [ Index(value = ["name"]) ])data class SongEntityWith indexed column name, when searching for the song “Untitled MELODY”, the database can quickly locate the row. Instead of full table scan, it looks-up through indexed structure.
Here is a visualized index structure of our table:
[Object Music, SAMPLE song] / | \[Mock SYMPHONY] [Prototype Harmony] [Untitled MELODY]When inserting data, SQLite will insert indexed keys into a B-tree structure to enable faster searching. For example, when finding “Untitled MELODY,” it starts at the root node containing “Object Music” and “SAMPLE song,” then makes comparisons to move left or right at each step. Since “Untitled MELODY” is greater than both “Object Music” and “SAMPLE song,” it will move to the right child node and continue this process until it finds “Untitled MELODY.”
Compared to a full table scan, this is faster with time complexity of O(log n).
Practical Query Examples: Effective Use of Indexes
When searching in database to find related items, a practical method is using lowercase matching. We can achieve this by converting the column name to lowercase to compare with the input value in lowercase.
SELECT * FROM song WHERE LOWER(name) = 'untitled melody';This query works fine, but there is a performance issue. When using a function like LOWER() on a column, the database must perform the function on every row to convert it to lowercase then compare the value, resulting in a full table scan, and prevents the index being used efficiently, consequently increase complexity to O(n).
To avoid the full table scan, we should use the LIKE operator, which is case-insensitive. That means when the database traverse the B-tree, it can compare values case-insensitively to find “untitled melody” index.
SELECT * FROM song WHERE name LIKE 'untitled melody';We can also perform case-insensitive searches by using the COLLATE NOCASE collation.
SELECT * FROM song WHERE name = 'untitled melody' COLLATE NOCASE;With this approach, SQLite can use the index to perform the case-insensitive comparison efficiently, maintaining a time complexity of O(log n).
Optimizing Wildcard Searches with Indexing in SQLite
When using the LIKE operator in SQLite queries, the placement of wildcard may break the usage of database indexes. For example, we find a name that contains untitled content.
SELECT * FROM song WHERE name LIKE '%untitled%'Technically, B-tree indexes are efficient for prefix searches, meaning if the wildcard is on the left side, the B-tree cannot locate quickly. It means possibly any nodes may contains the value of “untitled”. This leads to a full table scan for each row to match the pattern, which has time complexity of O(n).
However, when using a wildcard on the right side, the B-tree can find the starting point of the prefix untitle% . It means all the child nodes of this starting point may contains the value, and the rest of nodes above it can be skipped, resulting in a time complexity of O(log n).
SELECT * FROM song WHERE name LIKE 'untitled%'Here is the summary table:
| Wildcard Placement | Example | Index Utilization | Time Complexity |
|---|---|---|---|
| Both sides | %untitled% | No | O(n) |
| Left side | %untitled | Yes | O(n) |
| Right side | untitled% | No | O(log n) |
After reading this, you may want to check whether wildcard on the left side is necessary in your queries. Normally, wildcards on the left side are used when the inserted data may contain spaces. To achieve a better performance, and utilize the indexing, consider cleaning data before inserting it.
Why Not Index Everything
While indexing can boost query performance, it can increase the database size. When doing insert, the database also need to build the B-tree index. This means that the write operations will be slower, including the INSERT, UPDATE and DELETE operations. Each time when we make change to a row the database also needs to update the index tree.
Here is a comparison table showing time complexity for each operations with and without indexes in SQLite:
| Operation | Without Index | With Index |
|---|---|---|
| INSERT | O(1) | O(log n) |
| UPDATE | O(n) | O(log n) |
| DELETE | O(n) | O(log n) |
| SELECT | O(n) | O(log n) |
By understanding these complexities, you can make a clear decision when and where to use indexes effectively.
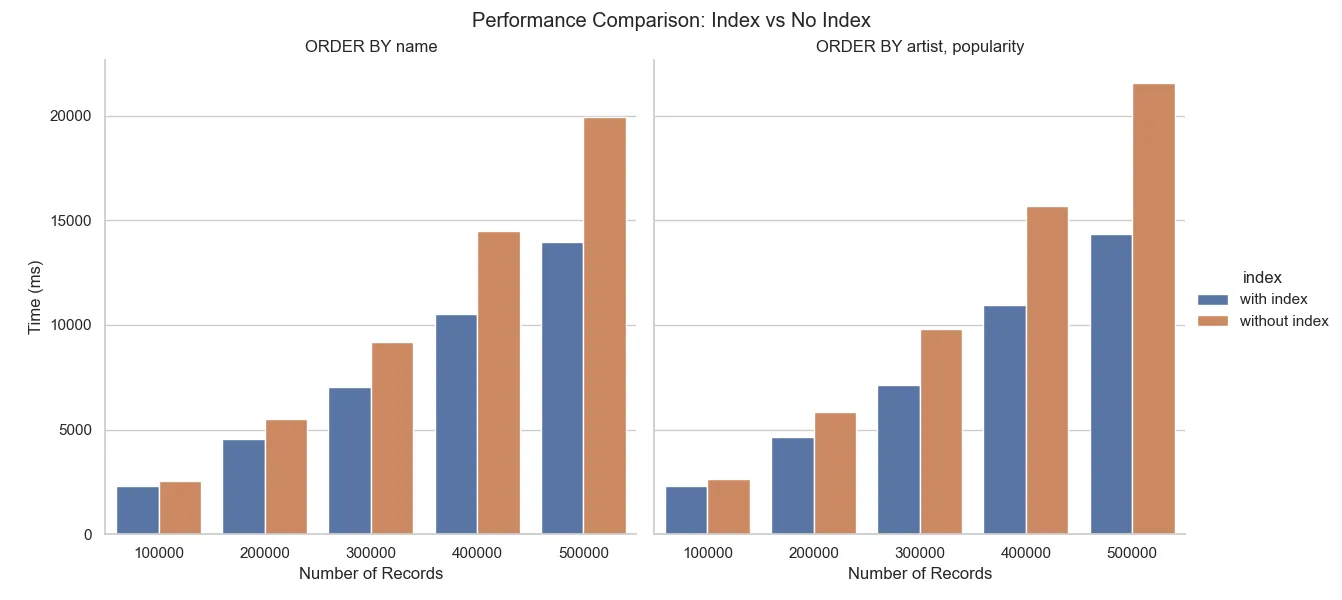
Benchmark Comparison: Index vs. No-Index Performance
To demonstrate the impact of indexing on query performance, I have conducted a benchmark comparison between indexed and non-indexed columns. This experiment focuses on the sort operations, which performs searching through all items to reorder them, making it noticeable in measurement comparing to a simple query.
Benchmark Queries
We have two queries to measure the performance:
- Single Column Sort
SELECT * FROM song ORDER BY name- Multi-Column Sort
SELECT * FROM song ORDER BY artist, popularityIndexing Entities
- Blue entity: properly indexed on relevant columns.
@Entity( tableName = "song", indices = [ Index(value = ["name"]), Index(value = ["artist", "popularity"]), ],)- Orange entity: indexed on popularity only, then we will see the performance of it in used with multiple conditions query.
@Entity( tableName = "song", indices = [ Index(value = ["popularity"]), ],)Benchmark Results
The dataset has a range from 100K to 500K rows to observe the performance differences. As a result, the queries with non-indexed columns experience significant slowdowns.
We also notice that the indexing only on popularity has poor performance when using in multiple query conditions (artist, popularity). Instead, we need to apply a composite index of the target columns that will be used in the query, which are both artist and popularity.
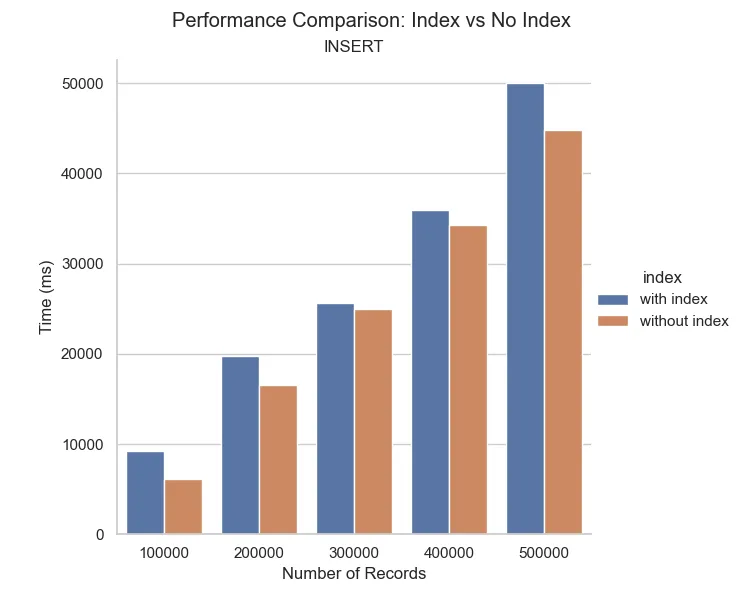
However, there is a significant slowdown with indexed table when inserting. It is because the database needs also perform building the index tree. It is included INSERT, UPDATE and DELETE operations.
Conclusion
While insert operations are slower on indexed columns due to additional steps to maintaining the index tree, selection queries are generally performed more frequently than insertions. This leads to better user experience when using the app as the display data are faster and more efficient.
In my experience, determining which columns to index often comes after the development phase of the app. By analyzing which columns are used frequently in ORDER BY clauses or have multiple conditions in queries, we can make decision to index on what columns.